What separates the brain from the other
mechanical parts of our body? It is its potential to learn and improve from its
past experiences. Similar is the task and purpose of machine learning. It
provides the ability to the system to learn from its past experiences without
being explicitly programmed.
 |
| Reference: https://becominghuman.ai/an-introduction-to-machine-learning-33a1b5d3a560 |
In machine learning and
statistics, classification can be defined as the problem of identifying a
pattern or defining a certain category amongst the set given of observations.
This thought and statement can be defined by considering a simple example of
classifying emails as “spam and non-spam” or sorting the list of voters on the
basis of their gender as “male or female”. Basically, taking a complex set of
data and distinguishing it on one or more criteria is classification.
An algorithm that
implements this classification of materials via an electronic device is called
a classifier. As of today, there are innumerable programs and codes
available to individuals to classify materials, the onus is on the user as
regards to which form of classification he/she desires from the algorithm. On a
broad basis, classification in machine learning is of two types- when the
outcome contains two options (classifying mail as spam or non-spam) or
multistage classification(where there are more than two options to the
situation). Here are a few of the endless machine learning classifiers:
Linear Regression and Logistic Regression
Linear Regression is the
approach to model the relationship between a dependent and an independent variable
while logistic regression uses a
logistic function to model a binary dependent variable.
Linear regression follows logistics regression
when it comes to popularity as a machine learning algorithm. While in a lot of
ways, these two are similar, the biggest difference lies in what they are used
for. For tasks comprising of forecasting or predicting values, linear
regression algorithm has an edge over logistic regression which is preferred
for classification tasks. Spam or not classification, fraudulent or not, etc
are some examples of usage of these algorithms in machine learning.
 |
| Reference: https://www.datacamp.com/community/tutorials/understanding-logistic-regression-python |
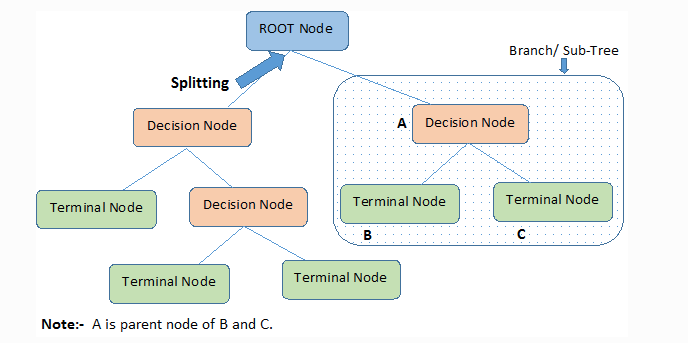
Decision tree
Decision tree forms a certain classification or regression in the form of a tree
structure, using the concept of branch, roots, tuples, and nodes. It uses an
if-then rule set which is exclusive for classification. The rules are learned
sequentially using the training data one at a time. Each time a rule is
conceptualized, the tuples covered by the rules are removed. This process is
continued on the training set until meeting a termination condition. The tree is constructed in
a way where it is recursive in its approach. All the attributes should be
categorical. Otherwise, they should be discretized in advance. Attributes at
the top of the tree have more impact on the classification and they are
identified using the information gain concept.
 |
| Reference: https://www.kdnuggets.com/2020/01/decision-tree-algorithm-explained.html |
Naive Bayes
A probabilistic classifier that is heavily
dependent on Bayes’ theorem. This theorem has a simple algorithm and can be
easily scaled to larger datasets, rather than being dependent on approximation.
It presumes that every variable in the dataset is independent of the other variables,
irrespective of their influence on the outcome. Naive Bayes is a very simple
algorithm to implement and good results have obtained in most cases. It can be
easily scalable to larger datasets since it takes linear time, rather than by
expensive iterative approximation as used for many other types of classifiers.
 |
| Reference: https://helloacm.com/how-to-use-naive-bayes-to-make-prediction-demonstration-via-sql/ |
The k-nearest-neighbours
The k-nearest-neighbours algorithm
is a supervised classification technique that uses closeness as a measure for similarity.
This algorithm labels points based on a bunch of previously labeled points. In
order to label a new point, it looks at its nearest labeled members. Closeness is typically expressed
in terms of a dissimilarity function. Once it checks with ‘k’ number of nearest
neighbours, it assigns a label based on whichever label most of the neighbours
have.
Geometric distance is an unreasonable or impractical measure to determine
the nearest item. If the type of input is, for instance, a text, it is unclear
as to how the variables are drawn in their geometric representation. Hence,
calculation of distance, unless well-calibrated on a case-by-case basis, is
vague and unreliable.
 |
| Reference: https://www.datacamp.com/community/tutorials/k-nearest-neighbor-classification-scikit-learn |
Random Forest
Random forests
are an ensemble learning method, combining one or more algorithms of same or different kinds of
classifying objects, for classification, regression, etc. It
operated by constructing several decision trees. Each tree provides its mean
prediction. The mode of the predictions of the individual trees is the output
of the entire algorithm. Working in a manner similar to that of decision trees,
it corrects for the latter’s habit of overfitting to the training set.
 |
| Reference: https://medium.com/@williamkoehrsen/random-forest-simple-explanation-377895a60d2d |
Support Vector Machine
Support-vector machine models with associated learning
algorithms that analyzes data used for regression and classification analysis.
Given a group of
coaching examples with each element marked as belonging to at least one or the opposite of two categories, an SVM training algorithm builds a model
that assigns new examples to at least one category or the opposite, making it a non-probabilistic binary linear
classifier. An SVM model may be a representation of the examples as points in space, mapped in order that the samples of the separate
categories are divided by a transparent gap that's as wide as possible. New examples are then mapped into that very same space and predicted
to belong to a category supported the side of the gap on which they fall.
 |
| Reference: https://en.wikipedia.org/wiki/Support-vector_machine |
Authors: Laksh Maheshwari, Ankit Lad, Aditya Kulkarni, Ayush Mehta, Jayant Majji.
Very Helpful
ReplyDeleteGood work
ReplyDeleteVery informative 👍🏻
ReplyDeleteGreat!!!!
ReplyDeleteSo insightful!!Thanks for amazing info
ReplyDeleteGood work
ReplyDeleteAmazing!!
Well written.
ReplyDeleteGreat work 👌🤘
ReplyDeleteGreat..
ReplyDeleteGreat work
ReplyDeleteNicely written, informative
ReplyDelete